Wyobraź sobie, że jeszcze przed opublikowaniem treści na stronie potrafisz oszacować, jak wysoko znajdzie się ona w wynikach Google. Brzmi kusząco? Nic dziwnego – każda firma i specjalista SEO marzy o recepturze na wysoką pozycję.
Zwiększenie ruchu organicznego dzięki SEO to przecież tańsza alternatywa dla płatnej reklamy. Jeśli nie uda się skutecznie wypozycjonować strony na szczyt wyników, czeka nas wydawanie fortuny na reklamy sponsorowane .
Od lat próbuje się więc rozszyfrować algorytm Google: analizować czynniki rankingowe i budować modele przewidujące, które strony zajmą czołowe miejsca
Najnowsze badanie naukowe rzuca na to zagadnienie nowe światło – sugeruje, że brakującym elementem układanki jest różnorodność danych. Gdy uwzględniono strony z wielu kategorii, dokładność prognoz pozycji w Google poprawiła się o ponad 25% . To ważna wiadomość dla marketerów i właścicieli witryn: być może warto poszerzyć horyzonty swojej analityki SEO o dane spoza własnej branży.

Znalezienie uniwersalnych czynników SEO to coś w rodzaju Świętego Graala marketingu w wyszukiwarkach. W przeszłości przeprowadzono wiele analiz stron internetowych, próbując ustalić, co łączy te najwyżej rankujące. Przykładowo wykazano, że topowe witryny często umieszczają słowo kluczowe w tytule strony, nagłówku H1 oraz w treści – i to w umiarkowanej liczbie powtórzeń (1–3 razy w tytule i opisie meta, 2–4 razy w tekście). Określono nawet optymalne długości elementów on-page: najlepsze strony miały średnio 8-wyrazowe tytuły, 10-wyrazowe meta opisy i 6-wyrazowe H1.
Dotychczasowe badania tego typu miały jednak istotne ograniczenie – najczęściej opierały się na dość jednorodnych zbiorach danych. Często analizowano strony tylko z jednej branży lub tematyki, ewentualnie z kilku pokrewnych kategorii. Taki brak różnorodności może zubażać wnioski. Modele uczone na jednym typie witryn nie „znają” wzorców obecnych w innych sektorach, a zestawy słów kluczowych bywały mało zróżnicowane pod względem popularności (pomijano np. frazy spoza wąskiej niszy czy o skrajnie różnym wolumenie wyszukiwań). Krótko mówiąc – brakowało szerokiej perspektywy.
Opisywane nowe badanie autorstwa Mohameda D. Almadhouna i Nurul H. A. H. Malim wypełnia tę lukę. Naukowcy postawili hipotezę, że trening modeli na stronach z wielu kategorii tematycznych da lepsze rezultaty niż ograniczanie się do jednej kategorii. Innymi słowy, chcieli sprawdzić, czy większa różnorodność w danych SEO przełoży się na trafniejsze prognozy pozycji. Tego typu podejście jest unikalne na tle wcześniejszych prac – to pierwsza tak kompleksowa próba uwzględnienia wielu branż jednocześnie w analizie czynników rankingowych.
Metoda badawcza
Aby zweryfikować postawioną hipotezę, badacze przeprowadzili zakrojony na szeroką skalę eksperyment z danymi SEO, obejmujący zbieranie informacji ze stron WWW i wyników wyszukiwania oraz uczenie modeli machine learning. Poniżej kluczowe etapy ich metodologii:
Dobór słów kluczowych
Przygotowano trzy zestawy po 100 anglojęzycznych słów kluczowych każdy. Pierwszy zestaw dotyczył jednej kategorii tematycznej („gifts” – branża prezentów), drugi również jednej kategorii („accounting” – strony o księgowości), a trzeci zawierał słowa kluczowe z 16 różnych kategorii tematycznych. Frazy dobrano tak, by obejmowały zarówno bardzo popularne (miliony zapytań miesięcznie), jak i niszowe (setki wyszukiwań) – dzięki temu zakres konkurencyjności i popularności był szeroki.
Scrapowanie wyników Google
Dla każdego słowa kluczowego z listy pobrano wyniki wyszukiwania Google przy użyciu automatycznego narzędzia Apify. Ustawiono pozyskiwanie maksymalnie 3 stron wyników na zapytanie (tj. do 30 wyników, 10 na stronę) w trybie wyszukiwania desktopowego. Skupiono się na wynikach organicznych – dane zawierały informację o pozycji URL-a w rankingu, numerze strony wyników, rodzaju wyniku (organiczny vs. reklamowy) oraz oczywiście adres URL i zapytanie, dla którego się pojawił. Ponieważ Google dominuje globalnie (>90% udziału w rynku wyszukiwarek), badacze skoncentrowali się właśnie na nim. Uzyskano w ten sposób tysiące adresów stron pojawiających się na różne zapytania.
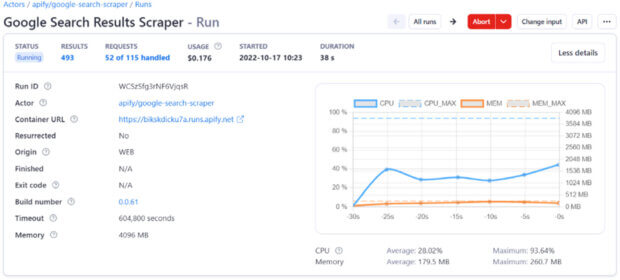
Crawlowanie stron i ekstrakcja czynników on-page
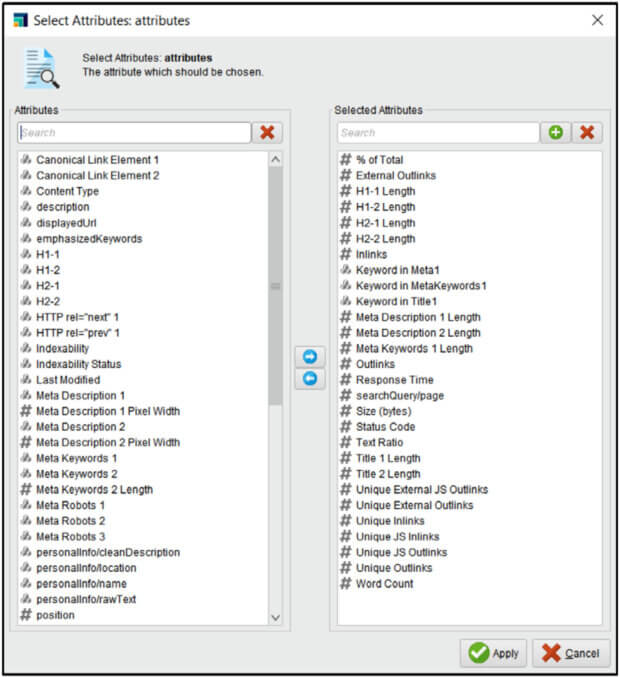
Następnie zebrane adresy URL zostały przekazane do narzędzia Screaming Frog SEO Spider, aby wyciągnąć z każdej strony dziesiątki metryk on-page. Screaming Frog potrafi automatycznie przeanalizować strukturę strony i meta tagi – w tym przypadku wygenerował początkowo aż 71 różnych atrybutów dla każdej strony (np. tytuł, opis, nagłówki, liczba słów, rozmiar strony, status HTTP, liczba linków wychodzących, itp.). Nie wszystkie były potrzebne – wykluczono pola tekstowe (same treści tagów), unikalne identyfikatory czy inne nieinformatywne kolumny. Skupiono się na tych parametrach, które mogły wpływać na SEO. Screaming Frog umożliwił też eksport danych do CSV, co ułatwiło dalszą obróbkę.
Scalenie i przygotowanie danych
Dane z Apify (dot. pozycji w SERP) oraz ze Screaming Frog (dot. cech on-page) zostały połączone dla każdej strony. Posłużono się tu oprogramowaniem RapidMiner, które pozwoliło zautomatyzować łączenie informacji po URL oraz oczyścić zbiór. Usunięto duplikaty (ta sama strona mogła pojawić się dla wielu słów kluczowych – takich duplikatów nie usuwano w wynikach Google, ale w danych on-page zcrawlowanych mogły wystąpić powtórzenia tego samego URL). Wyeliminowano też wszystkie wiersze dotyczące reklam (wyniki płatne) oraz wpisy z brakującymi danymi, pozostawiając wyłącznie organiczne wyniki z kompletem atrybutów. Po tej filtracji otrzymano trzy gotowe zbiory danych o następujących rozmiarach: 2596 stron dla zestawu wielotematycznego, 2622 stron dla kategorii „accounting” oraz 2151 stron dla kategorii „gifts”. Widać, że choć początkowo liczba zapytań była równa (100 w każdej grupie), ostateczna liczba zebranych stron różniła się – wynikało to z odmiennej liczby zduplikowanych i reklamowych wyników w każdej domenie tematycznej.
Inżynieria cech i atrybuty SEO
Zanim przystąpiono do trenowania modeli, badacze wzbogacili jeszcze dane o parę stworzonych atrybutów. Między innymi dla każdej strony sprawdzono, czy słowo kluczowe wyszukane przez użytkownika występuje w jej tytule, opisie meta oraz tagach meta keywords – i dodano specjalne cechy logiczne sygnalizujące taką obecność. Dzięki temu mogli analizować wpływ obecności frazy kluczowej w tych ważnych elementach on-page. Następnie określono finalny zestaw cech do modelowania – odrzucono atrybuty nieprzydatne w przewidywaniu rankingu (np. status HTTP jako kod liczbowy) i pozostawiono te potencjalnie istotne (pełna lista wybranych cech jest na diagramie poniżej).
Trening modeli i predykcja rankingu
Tak przygotowane zbiory posłużyły do zbudowania modeli uczących się przewidywać pozycję strony na podstawie cech SEO. Wykorzystano kilka różnych algorytmów uczenia maszynowego – od prostych drzew decyzyjnych i k-NN, przez naiwny klasyfikator Bayesa, po bardziej zaawansowane metody zespołowe jak Random Forest, XGBoost czy Gradient Boosted Trees, a także prostą sieć neuronową (“Deep Learning”) i regresję logistyczną (w wersji ważonej). Łącznie przetestowano 8 typów klasyfikatorów. Modele trenowano osobno na każdym z trzech zestawów danych (osobno dla multi-kategorii, gifts i accounting), aby móc je potem porównać. Początkowo zadanie postawione modelom miało charakter wieloklasowy – należało sklasyfikować stronę do odpowiedniej dziesiątki wyników (tzn. czy strona znalazła się na 1. stronie wyników, 2. stronie czy 3. stronie SERP). Taki trzyklasowy podział odpowiada realiom (top10 to pierwsza strona Google, wyniki 11–20 to druga strona, 21–30 – trzecia strona). Wewnątrz zbiorów treningowych wykorzystano walidację krzyżową (10-krotną) dla oceny skuteczności modeli. Następnie, na bazie wniosków, przeprowadzono też eksperymenty z klasyfikacją binarną – sprowadzając problem do odróżnienia, czy dana strona jest w Top 10 czy nie (czyli czy mieści się na pierwszej stronie wyników, czy spada poza nią).
Porównanie scenariuszy
Kluczowym elementem było porównanie, jak różne zestawy danych wpływają na skuteczność predykcji. W tym celu autorzy najpierw sprawdzili, które algorytmy radzą sobie najlepiej na poszczególnych zbiorach (porównując wyniki dla modeli uczonych na danych jednorodnych vs. zdywersyfikowanych). Następnie wykonano test symulujący rzeczywiste zastosowanie: model nauczony na jednym rodzaju danych przetestowano na stronach spoza tej kategorii. Na przykład klasyfikator wytrenowany na stronach z kategorii „gifts” sprawdzono na stronach z innych branż, aby zobaczyć, czy poradzi sobie z uogólnieniem wiedzy. Taki test pokazał, jak bardzo ograniczony jest model uczony na jednym typie witryn – to tak, jakby specjalista SEO od e-commerce próbował przewidywać rankingi stron rządowych czy medycznych bazując tylko na swoim wąskim doświadczeniu.
Analiza czynników rankingowych
Ostatnim etapem była analiza korelacji między poszczególnymi cechami SEO a osiąganą pozycją strony. Innymi słowy, sprawdzono, które parametry on-page mają statystycznie najsilniejszy związek z wysokim miejscem w rankingu Google. Pozwoliło to wskazać najważniejsze czynniki SEO spośród badanych – praktycznie tworząc listę „top czynników”, które wyróżniają najlepiej pozycjonujące się strony.
Wyniki badania
Lepsze wyniki dzięki różnorodności danych. Już pierwsze porównania potwierdziły przypuszczenia badaczy – modele uczone na zróżnicowanym, wielokategoriowym zbiorze danych osiągały znacznie lepszą skuteczność niż te trenowane na jednej kategorii stron. W 6 na 8 testowanych algorytmów dokładność klasyfikacji była najwyższa właśnie przy wykorzystaniu danych z wielu branż jednocześnie. Co więcej, najlepszy okazał się model z rodziny Gradient Boosted Trees (GBTs), który na zbiorze wielotematycznym uzyskał najwyższe wyniki spośród wszystkich klasyfikatorów . Łącznie odnotowano poprawę skuteczności o ponad 25% dzięki uwzględnieniu wielobranżowych danych względem danych jednorodnych. Dla zobrazowania skali: najlepszy model (GBT) osiągnął ok. 77,6% dokładności, przewidując której strony wyników docelowo znajdzie się dana strona (czyli 3 klasy: Top10, pozycje 11–20 lub 21–30), podczas gdy analogiczny model uczony na danych z pojedynczej kategorii był wyraźnie gorszy. Co więcej, gdy uproszczono zadanie do klasyfikacji binarnej (Top 10 vs. reszta), skuteczność modelu GBT wzrosła aż do 86,6%. Oznacza to, że mając informacje o on-page SEO danej strony, model potrafił z ~86-procentową trafnością stwierdzić, czy strona ląduje na pierwszej stronie wyników Google, czy nie – imponujący wynik jak na tak złożony problem.
Co istotne, przewaga danych wielotematycznych uwidoczniła się szczególnie w scenariuszu symulującym praktyczne zastosowanie modeli. Gdy model wyszkolony tylko na stronach z jednej branży próbowano zastosować do przewidywania pozycji stron z innych kategorii, jego wyniki drastycznie spadły. Na przykład, model trenowany wyłącznie na danych z kategorii „gifts” (prezenty/e-commerce) poprawnie klasyfikował pozycje stron z szerszego przekroju tematów tylko w 31,7% przypadków. Podobnie model uczony na stronach księgowo-finansowych osiągnął zaledwie 57,3% trafności poza swoją domeną. Dla porównania, model wytrenowany na zróżnicowanym zestawie od początku utrzymał wysoką skuteczność (~76–77% poprawnych przewidywań) również dla dowolnych stron spoza trening . To tak, jakby uniwersalny specjalista SEO radził sobie znacznie lepiej niż specjalista skupiony tylko na jednej niszy – szersza wiedza (więcej kategorii) przełożyła się na lepszą uogólnioną skuteczność. Wyniki te jednoznacznie potwierdziły hipotezę badaczy: aby budować wiarygodne modele predykcji pozycji w SERP, lepiej szkolić je na zróżnicowanych danych, niż na stronach z jednej branży.
Najważniejsze czynniki SEO wpływające na pozycję
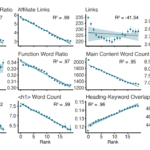
Analiza korelacji cech on-page z rankingiem Google przyniosła równie ciekawe rezultaty. Spośród kilkudziesięciu badanych parametrów wyłoniono top 5 czynników SEO najmocniej powiązanych z wysoką pozycją strony w wynikach organicznych:
Liczba unikalnych linków wewnętrznych
Im więcej różnych podstron w obrębie serwisu linkuje do danej strony, tym wyższa jej pozycja. Innymi słowy, silnie liczy się wewnętrzne linkowanie – strony dobrze podlinkowane w strukturze witryny mają lepsze wyniki.
Procent podstron linkujących wewnętrznie
Na którym miejscu w hierarchii strony stoi dana podstrona. Mierzono to jako odsetek unikalnych linkujących podstron względem łącznej liczby stron w witrynie. Jeśli duży ułamek wszystkich podstron zawiera link do danej strony, świadczy to o jej centralnej roli w serwisie (np. strona główna zwykle ma wiele linków z różnych miejsc) i koreluje to z lepszym rankingiem.
Liczba unikalnych linków zewnętrznych (wychodzących)
Strony zawierające więcej unikalnych linków wychodzących (do różnych domen) miały tendencję do wyższych pozycji. Może to świadczyć o tym, że bogate w źródła, wartościowe strony (np. artykuły z linkami do źródeł) lepiej się pozycjonują.
Czas ładowania strony (response time)
Szybsze strony osiągały wyższe pozycje. Długi czas odpowiedzi serwera korelował negatywnie z rankingiem, co potwierdza znaczenie wydajności i czynników Core Web Vitals dla SEO.
Długość treści (word count)
Liczba słów na stronie również znalazła się w czołówce czynników. Strony z obszerniejszą treścią (bogatsze w content) generalnie plasowały się wyżej niż strony z krótkim tekstem.
Te pięć czynników okazało się najmocniej powiązane z wysokim rankingiem Google w badanym zbiorze. W praktyce nie powinno dziwić, że linkowanie wewnętrzne zajęło pierwsze miejsce – wskazuje ono na znaczenie strony w ramach serwisu, co pośrednio może sygnalizować Google’owi ważność treści. Potwierdziło to zresztą wprost konkluzję badania: najlepszym czynnikiem on-page okazało się właśnie linkowanie wewnętrzne.
Co zaskakujące, analiza wykazała ciekawy szczegół dotyczący użycia słów kluczowych: obecność wyszukiwanego słowa kluczowego w meta opisie strony okazała się istotniejsza niż w tytule czy nagłówku. Innymi słowy, spośród czynników związanych z umiejscowieniem frazy kluczowej, to meta description miało najwyższą korelację z dobrą pozycją. Jest to w pewnym sensie kontraintuicyjne – powszechnie uważa się, że tytuł strony (title tag) oraz nagłówki H1 są kluczowe dla SEO, tymczasem w tym badaniu nie znalazły się one w ścisłej czołówce czynników korelujących z rankingiem. Trzeba jednak podkreślić, że mówimy tu o korelacji, a nie pewnym dowodzie przyczynowo-skutkowym. Możliwe, że najlepsze strony jednocześnie mają dobrze zoptymalizowane meta opisy (co poprawia CTR w SERP) i to pośrednio przekłada się na ich sukces. Niemniej, wynik ten przypomina, aby nie lekceważyć meta opisu – dobrze dobrana fraza kluczowa w opisie może pomóc, nawet jeśli algorytm główny Google nie wykorzystuje meta description bezpośrednio do rankingu.
Znaczenie wyników
Wyniki badania mają istotne implikacje dla praktyki SEO i digital marketingu. Przede wszystkim, potwierdzają coś, co doświadczeni specjaliści często przeczuwali: analizując SEO, warto wyjść poza bańkę własnej branży. Modele oparte na danych z wielu sektorów spisywały się wyraźnie lepiej – to sygnał dla marketerów, by przy formułowaniu strategii SEO czerpać inspiracje z różnych źródeł. Jeśli do tej pory ktoś opierał swoje wnioski wyłącznie na audycie kilku konkurentów z wąskiej niszy, powinien rozważyć poszerzenie analiz o strony spoza tej niszy. Może się okazać, że np. serwisy newsowe, blogi czy strony rządowe kryją wskazówki, które ulepszą strategię e-commerce – i na odwrót. Różnorodność danych daje pełniejszy obraz SEO, a to badanie dostarczyło na to liczbowych dowodów.
Po drugie, praca Almadhouna i Malim przekłada się na konkretne rekomendacje optymalizacyjne. Skoro wiemy, że wewnętrzne linkowanie to czynnik najmocniej związany z wysoką pozycją, warto przyjrzeć się strukturze swojej witryny. Czy najważniejsze strony (np. kluczowe produkty lub artykuły) są podlinkowane z wielu miejsc na stronie? Jeśli nie, to sygnał, by popracować nad architekturą informacji – np. dodając linki wewnętrzne w odpowiednich kontekstach, tworząc powiązane sekcje typu „Podobne artykuły” czy pillar pages zbierające linki do ważnych podstron. Badanie naukowe dostarcza tu twardego potwierdzenia dla praktyki: linkowanie wewnętrzne się opłaca (i to nie tylko dla ułatwienia nawigacji użytkownikom, ale ewidentnie także dla lepszej oceny przez algorytm).
Kolejnym wnioskiem jest podkreślenie roli czynników technicznych i jakości treści. Szybko ładująca się strona z obszerną, wartościową treścią ma przewagę nad wolną witryną z ubogim contentem – to potwierdza wnioski płynące już od jakiegoś czasu z aktualizacji Google (Core Web Vitals, E-E-A-T itp.). Marketerzy powinni więc inwestować nie tylko w słowa kluczowe, ale i w ulepszanie UX i wydajności. W praktyce: optymalizacja obrazków, używanie CDN, czysty kod – to wszystko pośrednio wspiera SEO, co liczby z eksperymentu również zdają się odzwierciedlać.
Ciekawym odkryciem, mogącym wpłynąć na codzienną pracę SEO-wca, jest kwestia meta description. Wielu specjalistów traktuje opis meta jako element ważny głównie dla CTR (zachęcenia użytkownika do kliknięcia), często powtarzając, że „Google i tak nie bierze meta description pod uwagę przy ustalaniu rankingu”. Tymczasem wyniki omawianego badania wskazują, że strony mające słowo kluczowe w opisie meta częściej są wysoko – co sugeruje, iż pośrednio może to jednak pomagać w rankingu. Być może dobrze sformułowany opis zwiększa współczynnik kliknięć, a to z kolei wpływa na pozycję – tak czy inaczej, lepiej nie zostawiać meta opisu przypadkowi. Dla bezpieczeństwa warto umieścić w nim najważniejszą frazę (oczywiście sensownie i zachęcająco dla użytkownika), bo może to przynieść dodatkową korzyść SEO.
Wyniki badania warto też odnieść do wcześniejszych prac. Weźmy choćby wspomniane analizy, które skupiały się na jednym sektorze (np. tylko e-commerce z prezentami). Teraz, mając dane z wielobranżowego ujęcia, widzimy, że pewne czynniki są uniwersalne – np. wewnętrzne linkowanie czy szybkość strony pomagają niezależnie od tematyki – natomiast inne (jak obecność słowa kluczowego w tytule) mogą nie „przebijać się” jako kluczowe, gdy spojrzymy szerzej. To cenna wskazówka dla SEO: fundamenty dobre dla jednej branży okazują się słuszne w wielu innych. Możemy zatem ze spokojem polegać na takich filarach jak mocna architektura linków wewnętrznych, porządny content i optymalizacja techniczna – to nie są trendy jednosezonowe ani ograniczone do wybranej niszy, lecz potwierdzone w różnych kontekstach elementy sukcesu.
Wnioski
Badanie Almadhouna i Malim to krok naprzód w naukowym zgłębianiu SEO, ale jak każde, ma swoje ograniczenia i rodzi kolejne pytania. Po pierwsze, analizowano wyłącznie czynniki on-page (oraz wewnętrzne, ale wewnątrz witryny). Nie uwzględniono natomiast czynników off-page, jak profil backlinków czy sygnały społecznościowe. Nie znaczy to oczywiście, że linki zewnętrzne przestały być ważne – po prostu w tym eksperymencie skupiono się na tym, co można zmierzyć na samej stronie. Co to oznacza dla wniosków? Otóż fakt, że już same cechy on-page pozwoliły przewidywać rankingi z 77% trafnością (a Top10 vs reszta z 86% trafnością), jest naprawdę imponujący. Można przypuszczać, że dodanie informacji o mocnych backlinkach, autorytecie domeny czy innych czynnikach off-page jeszcze poprawiłoby wyniki modelu. Autorzy sami wskazują, że w przyszłości planują rozszerzyć pracę właśnie o czynniki off-page, by zwiększyć robustowość klasyfikatorów. To ważny kierunek – pełny model rankingu Google musi przecież łączyć oba światy: relewancję strony (on-page) i autorytet/popularność (off-page).
Kolejną kwestią jest generalizacja wyników. Badanie przeprowadzono dla zapytań anglojęzycznych w domyślnym ustawieniu wyszukiwarki Google (prawdopodobnie rynek USA). Czy w innych językach lub krajach zależności będą takie same? Możemy przypuszczać, że ogólne trendy (np. znaczenie linkowania wewnętrznego czy szybkości) pozostaną podobne, ale np. konkurencyjność rynków może wpływać na to, jak silny musi być dany czynnik. W mniej konkurencyjnych niszach może wystarczyć mniejsza liczba linków itp. Pytanie też, czy algorytm Google w różnych wersjach językowych tak samo traktuje meta description – to temat na osobne badania.
Warto zauważyć, że model predykcyjny z pracy Almadhouna i Malim nie jest przeznaczony do bezpośredniego użycia komercyjnego, ale pokazuje potencjał data science w SEO. Prawdopodobnie agencje SEO dysponujące dużymi bazami danych mogłyby pokusić się o stworzenie własnych modeli rank prediction – np. aby przewidzieć, które podstrony klienta mają szansę na Top10, a które wymagają poprawy on-page. Ten eksperyment pokazuje, że to realne. Oczywiście, nie należy traktować takiego modelu jako wyroczni – wszak Google ciągle ewoluuje, wprowadza zmiany w algorytmach (Core Updates) i personalizuje wyniki. Jednakże pewne fundamentalne zasady pozostają stałe. Trudno wyobrazić sobie nagłą zmianę, w której np. szybkość strony czy wewnętrzne linkowanie przestają mieć znaczenie. Dlatego wnioski z tego badania prawdopodobnie będą aktualne jeszcze przez długi czas, nawet jeśli dokładne wagi czynników mogą się zmieniać.
Dla czytelników – właścicieli stron i marketerów – nasuwa się kilka pytań: Czy powinienem teraz zmienić swoją strategię SEO? Jeśli Twoja strategia pomijała któreś z top czynników (np. nie dbałeś o linkowanie wewnętrzne albo lekceważyłeś meta opis), odpowiedź brzmi: warto rozważyć korektę kursu. Badanie dostarczyło naukowego potwierdzenia wielu zaleceń, które krążyły w branży. Czasem dopiero twarde dane przekonują decydentów – tutaj je mamy. Czy mam zacząć budować własny model AI do SEO? Niekoniecznie – nie każdy ma zasoby na trenowanie modeli, ale każdy może skorzystać z wniosków płynących z modeli już zbudowanych. Zamiast czystej intuicji, mamy liczby, które priorytetyzują działania: np. przyspiesz stronę, bo czas ładowania jest naprawdę istotny; rozbuduj treść, jeśli jest bardzo krótka; zadbaj o linkowanie wewnętrzne, bo może wynieść Cię ponad konkurencję.
Nie ulega wątpliwości, że przyszłość SEO będzie coraz bardziej data-driven. Już dziś duże firmy analizują miliony wyników, by zrozumieć algorytm. To badanie akademickie pokazuje, że metodami naukowymi też możemy odkryć praktyczne prawidłowości. Co dalej? Być może zobaczymy kolejne prace, włączające do modeli np. behawioralne sygnały użytkowników (CTR, time on site) czy wspomniane profile linków. Autorzy sugerują również usprawnienia typu strojenie hiperparametrów modeli ML, by wycisnąć z nich jeszcze więcej dokładności. Można sobie wyobrazić, że za jakiś czas model będzie trafnie przewidywał rankingi np. z 90% skutecznością – a wtedy być może stanie się elementem narzędzi SEO na równi z dzisiejszym audytem on-page. Oczywiście, algorytmy Google to ruchomy cel, więc ciągłe badania będą konieczne, by nadążyć za zmianami. Niemniej, fundamentalna lekcja z tej pracy pozostanie: im więcej spojrzeń z różnych stron, tym lepiej widzimy cały obraz. W SEO – tak jak w wielu dziedzinach – otwartość na dane spoza własnej bańki pozwala odkryć nowe możliwości poprawy i przewagi nad konkurencją.
Podumowanie
Podsumowując, opisywane badanie przynosi wieloaspektowe korzyści dla zrozumienia SEO. Pokazuje, że różnorodność stron (wiele kategorii) w analizie może znacznie zwiększyć trafność prognoz pozycji – co ma sens, bo Google obsługuje przecież zapytania ze wszystkich dziedzin życia, więc modele uczone na przekrojowych danych są bardziej “obeznane” z różnymi wzorcami. Wskazuje też konkretne obszary, na których powinni skupić się właściciele stron: wewnętrzna struktura linków, bogata treść, optymalizacja techniczna (szybkość) oraz dopracowane elementy on-page (meta tagi). To wszystko razem buduje stronę przyjazną zarówno użytkownikom, jak i algorytmom wyszukiwarki.
Dla osób z branży SEO i marketingu cyfrowego takie wyniki są niezwykle cenne – potwierdzają pewne intuicje liczbami i zachęcają do eksperymentowania z podejściem opartym na danych. W lekkim, przystępnym stylu starałem się tu przedstawić najważniejsze wnioski, ale to oczywiście tylko streszczenie. Zachęcam ambitnych czytelników do zgłębienia pełnej publikacji (szczegóły poniżej) – znajdziecie tam wykresy, tabele i opisy metod, które pozwolą lepiej zrozumieć, jak doszło do opisanych rezultatów. SEO to dynamiczna dziedzina, lecz oparta na pewnych stałych fundamentach. Badanie „Effects of Using Multi-Category Web Pages on Rank Estimation of Google Search Engine Results Page” przypomina nam o tych fundamentach i udowadnia, że nauka i praktyka marketingu internetowego mogą iść w parze, przynosząc wymierne efekty. Wykorzystajmy te wskazówki w naszych projektach – a kto wie, może uda się wspiąć na upragniony szczyt wyników wyszukiwania!
Dane techniczne publikacji
Tytuł oryginału: Effects of Using Multi-Category Web Pages on Rank Estimation of Google Search Engine Results Page
Autorzy: Mohamed D. Almadhoun, Nurul Hashimah Ahamed Hassain Malim
Opublikowano w: Web Intelligence (2025), vol. 23, nr 1, s. 39-55
DOI: https://doi.org/10.3233/WEB-230239
Artur Strzelecki
Ostatnie wpisy Artur Strzelecki (zobacz wszystkie)
- Festiwal SEO 2026 Katowice - 16 czerwca 2026
- Black Friday SEO 2025 - 28 listopada 2025
- Druga część webinaru z autorami książki „SEO w praktyce” - 25 listopada 2025