Czy wyszukiwarka internetowa może nie tylko znajdować informacje, ale także je rozumieć i od razu tłumaczyć użytkownikowi w zrozumiały sposób? Brzmi to jak science fiction, ale właśnie taką przyszłość obiecuje integracja dużych modeli językowych (LLM) z usługami wyszukiwarek. Dzięki połączeniu możliwości sztucznej inteligencji i wyszukiwarek, nasze codzienne poszukiwanie informacji może stać się bardziej inteligentne, efektywne i spersonalizowane niż kiedykolwiek.

Ta wizja już zaczyna się urzeczywistniać. W ostatnich latach pojawiły się pierwsze zwiastuny transformacji: wyszukiwarka Bing zintegrowała model GPT, a Google uruchomiło eksperymentalny tryb Search Generative Experience (SGE), w którym na zapytania użytkowników odpowiada rozbudowany fragment AI zamiast tradycyjnej listy linków.
Jak ujęła to Elizabeth Reid z zespołu Google, generatywne AI w wyszukiwaniu „pomaga szybciej zrozumieć temat, odkryć nowe punkty widzenia i łatwiej podjąć działanie”. Oznacza to, że wyszukiwarka staje się coraz bardziej “silnikiem odpowiedzi” niż spisem stron, co stanowi prawdziwą zmianę paradygmatu w korzystaniu z informacji.
Klasyczne SEO
Dla specjalistów z branży SEO i marketingu internetowego takie zmiany to jednocześnie wyzwanie i szansa. Pozycjonowanie stron w erze AI wymaga innego podejścia – tradycyjne techniki oparte na słowach kluczowych i PageRank (analiza linków) mogą okazać się niewystarczające. Już teraz mówi się, że dawne filary SEO, jak dobór fraz czy klasyczny link building, stopniowo ustępują miejsca naciskowi na autorytet, jakość i strukturalną użyteczność treści. W praktyce, aby utrzymać wysoki CTR i widoczność, firmy muszą zadbać, by ich treści były na tyle wartościowe i wiarygodne, żeby to właśnie z nich korzystały systemy AI przy generowaniu odpowiedzi dla użytkowników.
Od czasów pierwszych wyszukiwarek internetowych sposób wyszukiwania informacji uległ ogromnym przeobrażeniom. Początkowo liczyło się głównie proste dopasowanie słów kluczowych i mechanizm PageRank, czyli ocenianie stron na podstawie liczby oraz jakości linków prowadzących (linków zwrotnych). Taki model często promował ilość nad jakość – strony niskiej wartości potrafiły wysoko się pozycjonować dzięki agresywnym taktykom linkowym, dopóki Google nie ukróciło tych praktyk aktualizacjami w rodzaju Panda czy Pingwin.
Z czasem wyszukiwarki zaczęły rozumieć kontekst zapytań: przeszły od czysto literalnego dopasowania do podejścia semantycznego, w którym znaczenie i powiązania między pojęciami odgrywają kluczową rolę. Dzięki temu lepiej radzą sobie z złożonymi pytaniami i zapytaniami z tzw. długiego ogona (bardzo szczegółowymi, niszowymi frazami).
Rozwój modeli językowych
Równolegle obserwowaliśmy dynamiczny rozwój dużych modeli językowych. Już wcześniejsze algorytmy językowe (np. Google BERT w 2019 r.) poprawiały zrozumienie kontekstu, ale prawdziwy przełom nastąpił wraz z udostępnieniem modelu GPT-3, a następnie ChatGPT (2022), który spopularyzował możliwości LLM na masową skalę.
Miliony użytkowników doświadczyły, że AI potrafi odpowiadać na pytania całkiem jak człowiek. Nic dziwnego, że giganci tacy jak Microsoft i Google szybko zainteresowali się wykorzystaniem tej technologii w wyszukiwaniu. Microsoft zainwestował w OpenAI i zintegrował model GPT z wyszukiwarką Bing, zaś Google przedstawiło własnego chatbota Bard oraz wdrożyło AI do wyników wyszukiwania (wspomniany SGE). Co istotne, ChatGPT korzysta z wyników Bing jako zaplecza wiedzy – tym samym nawet pomijana dotąd wyszukiwarka Microsoftu nabrała znaczenia, zmuszając specjalistów SEO do monitorowania i pozycjonowania stron również tam, nie tylko w Google.
Integracja wyszukiwarek z modelami generatywnymi stała się też obiektem zainteresowań naukowych. Pojawiła się koncepcja RAG (Retrieval-Augmented Generation), czyli generowania odpowiedzi wspomaganego wyszukiwaniem – model językowy pobiera aktualne informacje z indeksu wyszukiwarki, aby udzielić precyzyjnej i aktualnej odpowiedzi.
Najnowsze badania naukowe idą jednak dalej. Haoyi Xiong i in. w pracy „When Search Engine Services Meet Large Language Models: Visions and Challenges” postawili pytanie: jak dokładnie połączenie LLM i wyszukiwarek może przynieść obopólne korzyści? W swojej analizie skupili się na dwóch kierunkach integracji: wykorzystaniu wyszukiwarek do usprawnienia modeli LLM oraz zastosowaniu LLM do ulepszania działania wyszukiwarek. Ta szeroka perspektywa pozwoliła zmapować zarówno obecny stan badań, jak i potencjalne kierunki rozwoju tej symbiozy technologii.
Wyszukiwarka i modele językowe
Autorzy omawianej publikacji przeprowadzili dogłębną analizę literaturową i przegląd istniejących rozwiązań, aby zbadać możliwości integracji LLM z wyszukiwarkami. Praca ma charakter koncepcyjny – nie opiera się na jednym eksperymencie, lecz na syntezie wielu badań i przykładów. Badacze wyróżnili dwa kluczowe podejścia (zgodnie z wcześniej wspomnianymi kierunkami Search4LLM oraz LLM4Search) i dla każdego z nich zidentyfikowali konkretne obszary zastosowań.
W ramach pierwszego podejścia przeanalizowano m.in. wykorzystanie danych z wyszukiwarek (takich jak zapytania użytkowników czy wyniki wyszukiwania) do trenowania i ulepszania modeli językowych oraz techniki typu learning-to-rank (uczenie do rangowania) jako element szkolenia LLM. W drugim podejściu prześledzono, jak modele językowe mogą wspomóc działanie wyszukiwarki – od automatycznego podsumowywania treści stron na potrzeby indeksowania, przez optymalizację interpretacji zapytań, po inteligentne ocenianie relewancji wyników i generowanie adnotacji do algorytmów rankingowych. Autorzy omówili także wyzwania etyczne i techniczne takiej integracji oraz zaproponowali kierunki dalszych badań potrzebne, by te wizje wdrożyć w praktyce.
Badacze zidentyfikowali szereg konkretnych sposobów, w jakie synergia wyszukiwarek i LLM może usprawnić obie te technologie. Najważniejsze wnioski podzielono na dwie grupy: Search4LLM (wykorzystanie wyszukiwarki do ulepszania modelu językowego) oraz LLM4Search (wykorzystanie modelu do ulepszania wyszukiwarki). Poniżej przedstawiam te odkrycia w przystępny sposób, wraz z przykładami.
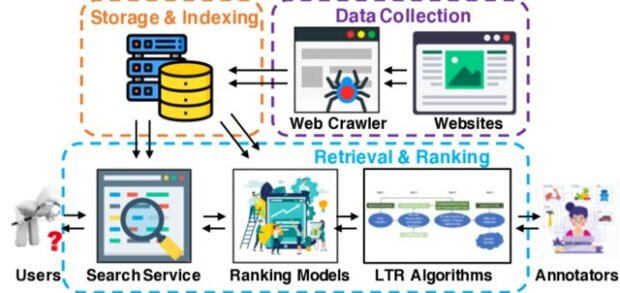
Search4LLM – jak wyszukiwarka wspomaga model językowy
W tym scenariuszu to wyszukiwarka „pracuje” na rzecz AI. Analiza wykazała cztery główne korzyści z wykorzystania usług wyszukiwania do rozwijania LLM.
Niewyczerpane zasoby danych treningowych
Wyszukiwarki przetwarzają codziennie miliardy zapytań od użytkowników (Google obsługuje ok. 8,5 miliarda wyszukiwań dziennie), a w indeksach przechowują kopie ogromnej części Internetu. Te bogate, zróżnicowane zbiory danych – od popularnych pytań po niszowe frazy z długiego ogona – mogą posłużyć jako materiał do trenowania i doskonalenia LLM. Model uczony na rzeczywistych zapytaniach i wynikach wyszukiwania lepiej rozumie, jakich odpowiedzi oczekują ludzie i jakie informacje są dla nich przydatne.
Wsparcie przy udzielaniu odpowiedzi (dostęp do aktualnej wiedzy)
Integracja LLM z wyszukiwarką pozwala modelowi językowemu na bieżąco pobierać z sieci najważniejsze informacje potrzebne do odpowiedzi. Gdy model napotka pytanie spoza swojej bazy wiedzy lub wymagające aktualnych danych (np. „czy dzisiaj jest protest komunikacji miejskiej?”), może automatycznie zadać zapytanie do wyszukiwarki, znaleźć najbardziej trafne dokumenty i na ich podstawie zsyntetyzować odpowiedź dla użytkownika. Dzięki temu odpowiedzi AI stają się bardziej precyzyjne i oparte na faktach, zamiast polegać wyłącznie na statycznej wiedzy z treningu.
Nauka przez rankingi (ulepszanie precyzji LLM)
Wyszukiwarki od lat wykorzystują algorytmy learning-to-rank do ustawiania wyników w kolejności odpowiadającej intencji użytkownika. Twórcy badania zauważają, że można takie podejście wykorzystać do trenowania LLM – model uczony na zadaniach, gdzie musi wybrać lub ocenić najbardziej relewantną odpowiedź na wzór rankera, nabiera umiejętności precyzyjniejszego formułowania odpowiedzi. To tak, jakby LLM uczył się od wyszukiwarki, które informacje są istotniejsze, a które mniej ważne dla użytkownika. W efekcie model może udzielać bardziej trafnych i uporządkowanych odpowiedzi.
Zawsze aktualne informacje
Klasyczne modele językowe mają wbudowaną wiedzę z momentu treningu i z czasem się „starzeją” – nie wiedzą, co wydarzyło się po dacie zakończenia ich szkolenia. Połączenie z wyszukiwarką rozwiązuje ten problem, bo LLM może na bieżąco uzupełniać swoją odpowiedź najnowszymi informacjami z sieci. Nawet jeśli świat się zmienia z dnia na dzień, model podłączony do aktualnych wyników wyszukiwania dostarczy świeżych, aktualnych odpowiedzi (np. najnowsze wyniki wyborów, aktualne kursy walut, nowe produkty na rynku itp.). Dzięki temu integracja Search4LLM sprawia, że odpowiedzi AI są zawsze na czasie i użyteczne z punktu widzenia użytkownika.
LLM4Search – jak model językowy wspomaga wyszukiwarkę
Druga grupa wniosków dotyczy odwrotnej relacji. To model językowy pracuje na rzecz ulepszenia działania wyszukiwarki. Tutaj również wyróżniono cztery kluczowe obszary zastosowań.
Automatyczne podsumowywanie i ekstrakcja danych ze stron
LLM mogą czytać i rozumieć całe dokumenty internetowe, a następnie tworzyć z nich zwięzłe podsumowania lub wyodrębniać kluczowe informacje. W kontekście wyszukiwarki oznacza to możliwość tworzenia lepszych opisów stron w indeksie (metadanych) lub nawet automatycznego generowania fragmentów wyników (snippetów) o wysokiej jakości. Przykładowo, zamiast polegać wyłącznie na słowach kluczowych, wyszukiwarka może wykorzystać streszczenie od LLM, by dokładniej zrozumieć, o czym jest dana strona i jak bardzo jest ona związana z zapytaniem użytkownika.
Lepsze zrozumienie zapytań i intencji użytkownika
Duże modele językowe świetnie radzą sobie z interpretacją języka naturalnego, synonimów czy nietypowych sformułowań. Można je wykorzystać do optymalizacji zapytań – np. automatycznego poprawiania literówek, sugerowania lepszych sformułowań lub rozbijania złożonego pytania na prostsze podzapytania. W efekcie nawet dość niejasne czy potocznie zadane pytanie użytkownika może zostać przeformułowane tak, aby wyszukiwarka zrozumiała właściwy zamiar. To trochę tak, jakby LLM pełnił rolę tłumacza między użytkownikiem a silnikiem wyszukiwania, dbając o to, by pytanie było jasne i “zrozumiałe” dla algorytmu.
Inteligentniejsze rankingowanie wyników
Klasyczne rankingi opierają się na dziesiątkach czynników (od dopasowania słów po linkowanie wewnętrzne i zewnętrzne), ale LLM daje możliwość analizy treści na wyższym poziomie „zrozumienia”. Model może ocenić kontekst i jakość całego tekstu na stronie, a nie tylko patrzeć na występowanie słów kluczowych. Dzięki temu może wspomóc algorytm sortowania wyników, wskazując, które strony są merytorycznie bardziej wartościowe dla danego tematu. LLM potrafi ocenić relewancję dokumentu podobnie jak człowiek – biorąc pod uwagę sens i kompletność informacji – co pozwala lepiej ułożyć listę wyników (ważne treści wyżej, mniej przydatne niżej). Takie podejście może wpłynąć pozytywnie na CTR w wynikach organicznych, ponieważ użytkownik szybciej zobaczy naprawdę przydatne odpowiedzi.
Automatyczne oznaczanie i uczenie systemu rankującego
Ostatnim wyróżnionym zastosowaniem jest wykorzystanie LLM do usprawnienia procesu uczenia samej wyszukiwarki. Tradycyjnie, aby ulepszyć algorytm rankingu, potrzeba wielu danych treningowych, np. informacji o tym, która strona powinna być wyżej od innej dla danego zapytania. Zdobywanie takich danych bywa kosztowne i czasochłonne (wymaga pracy ludzi-annotatorów). Model językowy może tu pełnić rolę automatycznego annotatora – generować wstępne oceny relewancji czy kategorie tematyczne stron, które potem posłużą do trenowania właściwych modeli rankujących. Dzięki temu rozwój wyszukiwarki może przyspieszyć, bo LLM dostarcza dodatkowych „oczu”, które oceniają strony, ucząc algorytmy, jak lepiej sortować wyniki.
Wpływ LLM na wyszukiwarki
Rewolucja LLM w wyszukiwaniu zmienia zasady gry dla SEO. Już pierwsze eksperymenty (jak SGE Google) pokazały, że użytkownicy otrzymują odpowiedzi bezpośrednio na stronach wyników, co zmniejsza ich skłonność do klikania w tradycyjne linki. Analitycy przewidzieli spadek ruchu organicznego dla wielu witryn – informacje podane od razu przez AI zaspokajają potrzeby użytkownika, przez co mniej osób przechodzi na strony źródłowe.
Dla marketerów oznacza to konieczność dostosowania strategii: sam współczynnik klikalności (CTR) przestaje być jedynym wyznacznikiem sukcesu, a monitorowanie pozycji musi brać pod uwagę nie tylko miejsce w rankingu, ale także widoczność treści w odpowiedziach generowanych przez AI. Co więcej, wyniki różnicują się w zależności od kontekstu użytkownika (historia wyszukiwania, lokalizacja), przez co rankingi stają się płynne i mniej uniwersalne.
Priorytetem staje się jakość, autorytet i przydatność treści. Duże modele językowe, analizując zasoby sieci, wybierają informacje od źródeł, którym mogą zaufać. W erze generatywnych odpowiedzi samo zdobycie wysokiej pozycji w Google to za mało – trzeba jeszcze stać się źródłem, z którego AI zechce skorzystać. W praktyce rośnie rola strategii content marketingu nastawionej na budowanie ekspertyzy i zaufania.
Publikowanie wyczerpujących, eksperckich treści, popartych danymi i doświadczeniem, staje się kluczowe. Google promuje podejście E-E-A-T (Experience, Expertise, Authority, Trust), które dotyczy teraz nie tylko rankingów, ale i selekcji treści przez AI. Szczególnie w wypadku zapytań wrażliwych, z kategorii YMYL (ang. Your Money or Your Life, np. medycyna, finanse), algorytmy będą wyjątkowo rygorystycznie oceniać wiarygodność strony. Model AI generujący odpowiedź na temat zdrowia chętniej przytoczy dane z serwisu rządowego lub renomowanej kliniki niż z anonimowego bloga. Dlatego dla witryn z sektora zdrowia, finansów czy prawa budowanie autorytetu (przez referencje, certyfikaty, opinie ekspertów) jest ważne.
SEO staje się bardziej techniczne i holistyczne zarazem. Aby zwiększyć szanse, że nasze treści zostaną odnalezione i zrozumiane przez modele AI, warto dbać o strukturę i oznakowanie informacji. Implementacja danych strukturalnych (np. schema.org dla artykułów, produktów, lokalizacji) pomaga algorytmom lepiej zrozumieć zawartość strony i kontekst informacji. Strona wzbogacona o uporządkowane dane (np. recenzje produktowe, FAQ, dane lokalne) może zostać łatwiej wychwycona jako wartościowe źródło faktów.
Równie ważna jest organizacja treści w obrębie serwisu – jasna struktura kategorii, logiczne linkowanie wewnętrzne i tworzenie tzw. klastrów tematycznych (pillar page + powiązane artykuły) buduje w oczach wyszukiwarki obraz eksperta w danym temacie. Taka spójność tematyczna zwiększa topical authority witryny, co wpływa na jej widoczność zarówno w tradycyjnych wynikach, jak i w odpowiedziach generowanych przez LLM.
Linki zwrotne i PageRank vs. treść i zaangażowanie. W świecie zdominowanym przez AI zmienia się także podejście do linków. Backlinki nadal są istotnym sygnałem – w końcu wskazują, że treść jest na tyle wartościowa, iż inne strony do niej odsyłają – lecz już nie wystarczy zdobyć ich jak najwięcej. Jak zauważono, liczy się nie liczba, a jakość, linki są użyteczne, ale nie zagwarantują pozycji, jeśli brakuje wartościowej treści i zainteresowania odbiorców.
Strategie czysto ilościowego link buildingu ustępują więc miejsca podejściu jakościowemu. Lepiej zainwestować w stworzenie materiału, który sam z siebie stanie się popularny (zdobędzie naturalne linki, udostępnienia w mediach społecznościowych), niż sztucznie mnożyć odnośniki z przypadkowych stron. Co więcej, modele AI analizujące treść mogą wykryć sygnały zaangażowania – np. że artykuł jest często cytowany, udostępniany, długo czytany przez użytkowników – i to te sygnały mogą w przyszłości ważyć więcej niż surowa liczba linków.
Lokalne SEO i personalizacja. Integracja AI oznacza również zmiany w obszarze pozycjonowania lokalnego. Zapytania lokalne coraz częściej skutkują bezpośrednią odpowiedzią AI w formie listy polecanych miejsc, czasem z pominięciem tradycyjnego pakietu map. System uczący się na podstawie opinii i ocen użytkowników może bardziej promować te firmy, które mają świetną reputację online. Według zapowiedzi, Bing i inne AI zamierzają wykorzystywać sygnały takie jak recenzje czy wzmianki w social media, by wyróżniać najbardziej cenione lokalne biznesy. Dla firm zatem kluczowe jest nie tylko klasyczne SEO lokalne (aktualne wpisy w Google Moja Firma, zgodne NAP, lokalne słowa kluczowe), ale i dbałość o opinie klientów oraz obecność w społecznościach internetowych.
Wyniki omawianych badań wskazują, że specjaliści SEO muszą ewoluować wraz z wyszukiwarkami. Konieczne jest szersze spojrzenie – już nie tylko optymalizacja pod algorytm, ale pod użytkownika i AI jednocześnie. Od działań typu content marketing (tworzenie naprawdę wartościowych treści, które zbudują markę jako eksperta), przez współpracę z zewnętrznymi mediami (aby zdobyć wzmianki i linki z wiarygodnych źródeł), aż po inwestycje w technologię (strukturyzacja danych, śledzenie nowinek jak Bing AI) – marketing internetowy musi dostosować się do nowego ekosystemu.
Na przykład, publikowanie eksperckich artykułów na branżowych portalach (artykuł sponsorowany lub gościnny) może budować autorytet i zwiększyć szansę, że nasze informacje zostaną zaciągnięte przez LLM. Firmy i agencje, które szybko przyswoją te lekcje, będą mogły skuteczniej konkurować o widoczność w nadchodzącej erze AI.
Nie tak łatwo połączyć LLM z wyszukiwarką
Choć perspektywa integracji LLM i wyszukiwarek jest ekscytująca, badanie podkreśla szereg wyzwań i otwartych kwestii, które wymagają uwagi zanim wizja stanie się w pełni rzeczywistością. Problem uprzedzeń i wiarygodności danych to jedno z nich – modele językowe uczą się na ogromnych zbiorach tekstu z Internetu, które niestety zawierają błędy, stronniczość lub przestarzałe informacje.
Istnieje ryzyko, że AI będzie wzmacniać popularne, ale nieprawdziwe przekonania lub faworyzować źródła prezentujące określony punkt widzenia. W kontekście SEO rodzi to pytanie, czy i jak można ”optymalizować” treści, by były poprawnie interpretowane przez AI, nie wprowadzając w błąd. Konieczne są prace nad metodami ograniczania błędów merytorycznych modelu (np. poprzez weryfikację odpowiedzi z wielu źródeł) oraz nad algorytmami odporności na manipulacje, tak by np. pojedyncza strona nie mogła łatwo ”zatruć” modelu powielanym fake newsem.
Wyzwania technologiczne i kosztowe również nie mogą zostać pominięte. Utrzymywanie dużego modelu językowego działającego w ramach usługi wyszukiwawczej wymaga olbrzymiej mocy obliczeniowej. Odpowiadanie na tysiące zapytań na sekundę przy użyciu LLM to koszt, na który pozwolić sobie mogą nieliczni – rodzi to obawy o mniejsze innowacje i konkurencję na rynku wyszukiwarek. Ponadto, model musi być ciągle aktualizowany nowymi danymi (czy to poprzez retrening, czy poprzez mechanizmy w stylu RAG opisane wcześniej).To z kolei wiąże się z kwestią skalowalności i architektury systemu.
Być może konieczne będzie przeprojektowanie klasycznych infrastruktur wyszukiwarek, by sprawnie łączyły indeksowanie miliardów stron z modułem generatywnym odpowiadającym w ułamku sekundy na pytania użytkowników. Autorzy badania zwracają uwagę, że utrzymanie aktualności modeli w obliczu nieustannie zmieniającej się sieci będzie stałym wyzwaniem – inaczej model szybko stanie się nieadekwatny do rzeczywistości.
Kwestie prywatności i etyki zyskują na wadze, gdy wyszukiwarki stają się bardziej ”inteligentne”. Personalizacja odpowiedzi oznacza, że systemy AI będą jeszcze intensywniej wykorzystywać dane o nas, takie jak historia wyszukiwań, lokalizacja i preferencje. Powstaje więc pytanie o granice – jak pogodzić bogate spersonalizowanie wyników z ochroną prywatności użytkowników?
Konieczna jest maksymalna transparentność co do tego, jakie dane są zbierane i jak wykorzystywane (by użytkownik mógł świadomie zdecydować, czy chce z nich korzystać). Również od strony etycznej, pojawia się problem odpowiedzialności za treść, bo jeśli AI wygeneruje szkodliwą lub wprowadzającą w błąd odpowiedź (np. w kwestii zdrowotnej), kto bierze za to odpowiedzialność – twórcy modelu, operator wyszukiwarki, a może nikt?
Takie dylematy prawne i moralne będą wymagały nowych regulacji oraz mechanizmów nadzoru. Już teraz trwają prace nad uczynieniem algorytmów bardziej przejrzystymi i weryfikowalnymi – tak, aby było wiadomo, na jakiej podstawie AI podjęła decyzję i z jakich źródeł skorzystała.
Wreszcie, integracja LLM w wyszukiwaniu może nieść nieprzewidziane konsekwencje dla systemu informacji w sieci. Jeśli użytkownicy coraz rzadziej będą odwiedzać bezpośrednio strony internetowe (zadowalając się odpowiedziami AI), wydawcy treści mogą stanąć przed problemem modelu biznesowego. Mniejszy ruch to mniej przychodów z reklam czy abonamentów, co z kolei może ograniczyć powstawanie nowych wartościowych treści. To rodzi otwarte pytanie: czy da się pogodzić wygodę użytkownika z interesem twórców treści?
Być może wyszukiwarki w przyszłości będą dzielić się częścią zysków lub udostępniać nowe formaty prezentacji, w których źródła informacji będą bardziej wyeksponowane (np. jako elementy multimedialne, karty informacyjne z linkiem). Na razie jednak brak jednoznacznej odpowiedzi, jak zapewnić symbiozę między AI a twórcami contentu.
Przed połączeniem LLM i wyszukiwarek stoi zarówno ogromna szansa, jak i wiele trudności. Konieczne będzie wspólne zaangażowanie inżynierów, ekspertów od SEO, specjalistów od prawa i etyków, by wypracować rozwiązania zapewniające wiarygodność, przejrzystość i sprawiedliwość nowej generacji wyszukiwania. Badania takie jak omawiane stanowią ważny głos w tej debacie – wskazują problemy i sugerują kierunki, ale ostateczny kształt przyszłego systemu informacji będzie zależał od decyzji podjętych przez wszystkie zainteresowane strony: firmy technologiczne, wydawców i nas – użytkowników.
Omawiane badanie „When Search Engine Services Meet Large Language Models: Visions and Challenges” (Xiong, Bian, Li, Li, Du, Wang, Yin, Helal – 2024) stanowi cenny wkład w zrozumienie tych przemian. Autorzy nie tylko przedstawili wizje potencjalnych zastosowań AI w wyszukiwaniu, ale też uczciwie wskazali wyzwania, przed jakimi staniemy na drodze do ich realizacji. Dla specjalistów SEO raport ten jest wartościową wskazówką, bo potwierdza, że kierunek obrany przez gigantów technologicznych (Google, Microsoft) jest trwały i warto już teraz inwestować w działania przygotowujące strony oraz strategię contentową na nadchodzącą erę.
Dane techniczne publikacji
- Autorzy: Haoyi Xiong, Jiang Bian, Yuchen Li, Xuhong Li, Mengnan Du, Shuaiqiang Wang, Dawei Yin, Sumi Helal
- Tytuł oryginalny: When Search Engine Services Meet Large Language Models: Visions and Challenges
- Opublikowano: IEEE Transactions on Services Computing, 2024, Vol. 17, No. 6, s. 4558–4577 (artykuł recenzowany).
- DOI: https://doi.org/10.1109/TSC.2024.3451185
Zapisz się na newsletter wypełniając pola poniżej. Będziesz na bieżąco ze wszystkimi wydarzeniami związanymi z Silesia SEM i informacjami o marketingu internetowym w sieci. Nie spamujemy.
Zostanie wysłany do Ciebie e-mail potwierdzający: przeczytaj zawarte w nim instrukcje, aby potwierdzić subskrypcję.
Artur Strzelecki
Ostatnie wpisy Artur Strzelecki (zobacz wszystkie)
- Festiwal SEO 2026 Katowice - 16 czerwca 2026
- Black Friday SEO 2025 - 28 listopada 2025
- Druga część webinaru z autorami książki „SEO w praktyce” - 25 listopada 2025