W artykule przeczytacie o własnych doświadczeniach i testach z tego jak obecnie działa lub nie działa rel=canonical i jego ustawienia w obrębie jednej lub wielu domen. Do podzielenia się testami zainspirował mnie wątek na grupie FB, gdzie autor pyta o możliwość wykorzystania czeskiego błędu przy przechwyceniu mocy domeny.

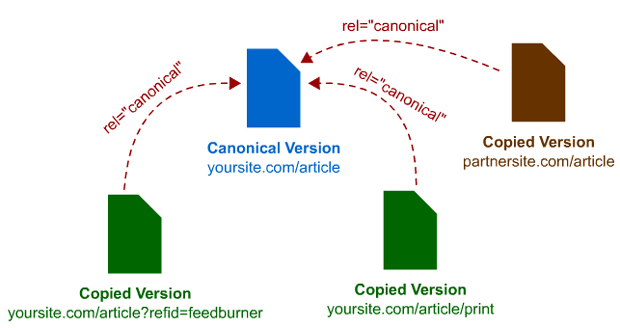
Kiedyś rel=canonical funkcjonował mniej więcej tak, jak na tym starym obrazku z archiwum MOZ.
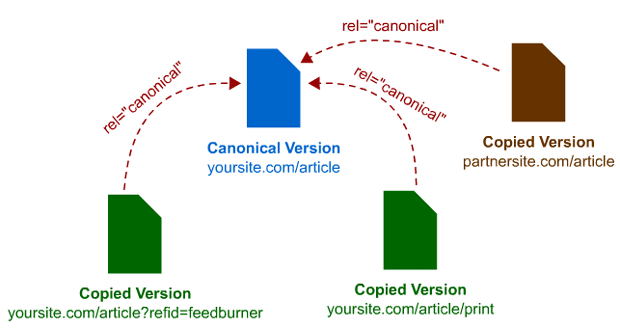 Zwróćcie uwagę na ten przykład. Według tego schematu, zewnętrzna domena oraz strony z tej samej domeny, które posiadają kanoniczne URLe, wskazują na oryginał, ten niebieski w środku. Tak było kiedyś, ale teraz już tak nie ma.
Zwróćcie uwagę na ten przykład. Według tego schematu, zewnętrzna domena oraz strony z tej samej domeny, które posiadają kanoniczne URLe, wskazują na oryginał, ten niebieski w środku. Tak było kiedyś, ale teraz już tak nie ma.
Obecnie mam na stronie ustawionych kilka adresów kanonicznych, które wyświetlają się w następujący sposób.
Przykład A:
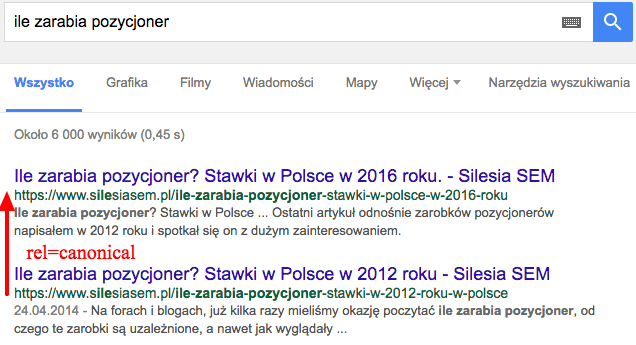 Opis: Adres kanoniczny jest ustawiony z postu z 2012 na 2016 rok, mimo to wyświetlają się oba.
Opis: Adres kanoniczny jest ustawiony z postu z 2012 na 2016 rok, mimo to wyświetlają się oba.
Przykład B
 Opis: Adres kanoniczny jest ustawiony z postu o aktualizacji Pingwin 2.1 na post o aktualizacji 3.0, mimo to wyświetlają się oba.
Opis: Adres kanoniczny jest ustawiony z postu o aktualizacji Pingwin 2.1 na post o aktualizacji 3.0, mimo to wyświetlają się oba.
Przykład C (obecnie nieaktywny)
Miałem ustawione adresy kanoniczne ze stron dotyczących poprzednich edycji Festiwalu SEO na aktualną edycję. Niestety, Google wyrzuciło z indeksu te stronę, na które wskazywały linki kanoniczne, więc założenia linków kanonicznych nie zadziałały.
Przykład D (od klienta)
Kupiłem dla klienta artykuł przez Whitepress. Wydawca trochę kombinował i ustawił w artykule sponsorowanym link kanoniczny, do strony do której miał prowadzić link z treści. Być może chciał, aby ten zakupiony artykuł nie pojawiał się w indeksie. Artykuł jest w indeksie, mimo ustawionego linku kanonicznego do innej domeny.
Przykład E (od klienta)
Jeden z artykułów na Silesia SEM oznaczyłem linkiem kanonicznym aby przekazywał moc na stronę klienta. Artykuł nadał był w indeksie, a stronie klienta to nie pomogło, zatem przywróciłem poprzednie ustawienia.
Przykład E (własny)
Jakiś czas temu został opublikowany przedruk artykułu „Pozycjonowanie umiera! Niech żyje Pozycjonowanie!” autorstwa Sławka Borowego. Artykuł ma ustawiony rel=canonical do źródła oraz link na dole do źródła. Nagłówek gdzieś dostał się do spamiarki i tych tytułów trochę jest w wynikach, ale próżno szukać tam źródła kanonicznego. Co ciekawe, druga kopia opublikowana pod adresem http://www.blog.go3.pl/pozycjonowanie-umiera-niech-zyje-pozycjonowanie/ nie znajduje się w indeksie, a ma tak samo ustawiony link kanoniczny.
Widzimy jak rel=canonical w różnych sytuacjach nie działa. Powstaje pytanie, zatem jak działa rel=canonical? Ktoś ma jakieś doświadczenia, co na pewno działa?
Zapisz się na newsletter wypełniając pola poniżej. Będziesz na bieżąco ze wszystkimi wydarzeniami związanymi z Silesia SEM i informacjami o marketingu internetowym w sieci. Nie spamujemy.
Zostanie wysłany do Ciebie e-mail potwierdzający: przeczytaj zawarte w nim instrukcje, aby potwierdzić subskrypcję.
Artur Strzelecki
Ostatnie wpisy Artur Strzelecki (zobacz wszystkie)
- Festiwal SEO 2026 Katowice - 16 czerwca 2026
- Black Friday SEO 2025 - 28 listopada 2025
- Druga część webinaru z autorami książki „SEO w praktyce” - 25 listopada 2025



Canonical zawsze był jedynie sugestią, a nie konkretną dyrektywą.
Czasami trudno jest znaleźć schemat działania, podobnie jak w Twoich przykładach. Podejrzewam (ale dowodów nie mam), że canonical może nie być w pełni samodzielnym sygnałem, a jego działanie uzależnione jest także od innych sygnałów.
Dobrze
Potwierdzają to chociażby ostatnie informacje o mobile-first indexation.
W aktualnej Google’owej dokumentacji Mobile SEO dla oddzielnych URLi to wersje mobile’owe wskazują tagiem kanonicznym na desktop. Tymczasem wg zmienionego indeksu (mobile-first), Google będzie chciał mobile wykorzystywać do oceny sygnałów i wartości treści – bez zmian tagów kanonicznych.
Ja aktualnie testuje i obserwuje dwa przypadki.
Przykład #1
Adres URL z parametrami, zawiera tag canonical na inny URL. Z tym, że canonical jest nadpisywany przez jQuery po wyrenderowaniu dokumentu.
Prawidłowy canonical jest widoczny dopiero w konsoli przeglądarki, a w źródle stary canonical. Tutaj to celowe działanie, gdyż Google dobrze radzi sobie z JS.
Przykład #2
Adres oznaczony tagiem kanonicznym na inny URL, nadal jest w indeksie. Po dodaniu noindex, follow cały czas widoczny w SERPach, ale zmiana miała miejsce stosunkowo niedawno, więc może to wymagać kilkukrotnych odwiedzin Googlebota. Prawidłowy URL nie znajduje się w indeksie wcale.
Pozdrawiam
Michał
Mam przypadek, gdzie ecommerce ma niektóre kategorie zrobione na mechanizmie wewnętrznej wyszukiwarki i żeby to jakoś obsłużyć ustawiliśmy canonical na główną stronę wyszukiwania.
Te podstrony w zasadniczo nie były indeksowane, ale ostatnio jednak zaczęły do indeksu trafiać.
Wychodzi, że canonical to taka luźna wskazówka dla algo, kiedy sam nie może się zdecydować.
Miałem swego czasu kilka artykułów, które posiadając przynależność do dwóch kategorii (i linkowania do dwóch osobnych stron) spowodowały pojawienie się w Search Console info o podwójnych meta opisach i tagach tytułowych. Po wprowadzeniu adresu kanonicznego do „właściwej” (jednej) strony problem duplikatów się rozwiązał
u mnie przypadek może nie aż tak drastyczny, ale pokazujący, że Google czyta canonical.
URLe na stronie są zdefiniowane by się wyświetlały tylko małymi literami. Jeśli wpiszesz adres z dużymi, to zostaniesz przekierowany (301) na wersję z małymi. W canonical jednak jest ustawiony adres z dużymi literami (np. /Marek-Gronski/ zamiast /marek-gronski/).
Google łyknął canonicala i pokazuje go w wynikach. So… canonical > 301?
Ja mam to na co dzień. Zmieniam URL mimo iż mam rel canonical Google pokazuje dwa te same wyniki.. uważajcie też aby adres kanoniczny wskazywał poprawny URL bo w innym przypadku może się to odbić na pozycji.. miałem taki problem w tagach i indeksacja URL w Google przez to stanęła w miejscu..
Od publikacji wpisu minęło trochę czasu ale pozwolę sobie dołożyć swoje 3 grosze do tematu zwłaszcza, że jestem po kilku testach. Kiedy powinno stosować się rel canonical? Wtedy kiedy odnosimy się do identycznych treści. Szyk zdań może być wymieszany jak przykładowo (wszystkim znany) przypadek z sortowaniem produktów w sklepie. W Waszych case’ach widać, że ta treść jest co najwyżej podobna ale nie identyczna. Doskonale ukazuje to przykład A z powyższego artykułu, Google zaindeksowało obie strony bo po prostu różnią się kilkoma detalami (które dla Google akurat są znaczące), gdyby były one identyczne zapewne jednej z nich w indeksie by nie było. Co więcej gdybym to ja był robotem G to również oznaczyłbym te dwa artykuły jako różne bo chciałbym wiedzieć ile zarabiało się w 2012 roku a ile 2016.
Z moich testów wynika, że przy identycznej treści rel canonical jest dosyć skuteczny a przy podobnej musimy trafić w 'punkt G’ aby zadziałało.