
Jakiś czas temu John Mueller w jednym z hangoutów wideo podczas Webmaster Central udzielił odpowiedzi na pytanie czy Google bierze pod uwagę URL, który nie jest linkiem, a tylko fragmentem zwykłego tekstu w postaci adresu URL. Innymi słowy, nie jest to znacznik A z atrybutem HREF i nie jest to klikalny link.
John odpowiedział, że tak, Google pobiera taki adres i jeśli wcześniej go nie znaleźli lub nie mieli informacji o nim w bazie to wysyłają tam swojego Googlebota. Robią to np. aby odkryć nowe domeny, które nie mają jeszcze linków, a ktoś tylko wspomniał o nich w treści. Taka wzmianka, zacytowanie adresu, nie przekazuje wartości PageRank, jedynie daj znać Googlebotowi, aby odwiedził dany adres.

Z jednej strony funkcja ma swoje zalety, bowiem sprawia, że jeśli ktoś wspomniał o jakimś adresie a nie ma do niego linków to Googlebot go odwiedzi. Jednak patrząc z praktycznego punktu widzenia, kto obecnie tworzy treść, która nie jest w żaden sposób podlinkowana?
Obecne aktualne wersje znanych i popularnych systemów CMS jak WordPress czy Joomla mają szereg mechanizmów, które sprawiają, że Googlebot natychmiast pojawia się na stronie po opublikowaniu treści. Najczęściej należą do nich generowanie mapy XML, umieszczanie informacji o nowo powstałej treści w mapie witryny dla użytkownika, czy też zwykłe umieszczenie nowego artykułu na stronie z linkiem wewnętrznym. Właściciele stron publikują także sygnały o nowych treściach w mediach społecznościowych lub rozsyłają przez e-mail link do nowego materiału.
Natomiast przytoczona funkcja ma też swoją co najmniej jedną wadę, na którą się przed chwilą natknąłem i sprawiła ona, że postanowiłem się bliżej przyjrzeć temu mechanizmowi. Przeglądając informacje w Narzędziach dla Webmasterów w zakładce Indeksowanie/Błędy indeksowania zauważyłem nowy błąd, którego wcześniej tam nie było. Zwykle co jakiś czas sprawdzam to miejsce, aby poszukać ewentualnych możliwości lepszego przekierowania linków, które prowadzą do stron nieistniejących lub poprawienia adresów w obecnych stronach albo skontaktowania się z webmasterami, którzy zamieścili do strony link, ale zrobili to wadliwie.
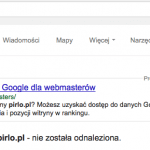
Na liście znajduje się link prowadzący do pliku XLS z danymi jakie niedawno były opracowane do artykułu o najbardziej opiniotwórczych polskich stronach i artykułach o SEO. W artykule znajdował się jeden, jedyny odnośnik do tego pliku XLS, ale jednak z jakiejś przyczyny Googlebot zobaczył też wersje z jednym dodatkowym znakiem na końcu ścieżki (zrzut poniżej).

Jak widać na przykładzie, na końcu ścieżki znalazł się dodatkowy znak, który sprawił, że powstał adres nie obsługiwany w tym momencie przez domenę. Adres prowadzi do katalogu, w którym przechowywane są wszystkie multimedia i z poziomu WordPressa zwracany jest błąd 404, ponieważ nie ma takiego pliku. Sprawdziłem co mogło sprawić, że Googlebot chciał odwiedzić taki adres, czyli gdzie został umieszczony link do tego adresu. Okazuje się, że linku nie ma.

W ostatniej zakładce widać, adres pod którym znajduje się link. Nawet zakładka jest zatytułowana „Link z domeny”.
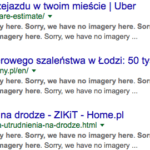
Po przejściu pod wskazany adres, okazuję się, że jest to automatycznie generowany spam, który miesza ze sobą różne ciągi znaków i produkuje kolejne podstrony. W dodatku to jeden z tych gorszych spamów bo z treścią dla widzów powyżej 18+.
 Jak się przyjrzycie to nie tylko zmieszało adres z tej domeny, ale także inne strony o SEO, m.in. blog od +Eweliny. Zwracając uwagę na szczegóły, na stronie nie ma ani jednego linka. Wszystko to pourywane lub zmodyfikowane w czystej postaci tekstowej adresy URL. Wyciągając na szybko wnioski, Googlebot wziął te adresy za dobrą monetę, postanowił odwiedzić, a kiedy mu się to nie udało, zgłosił błąd 404 w Narzędziach dla Webmasterów. Po prostu pięknie! Pozostaje tylko liczyć, że Google nie traktuje tego błędu na niekorzyść domeny, która go zwraca.
Jak się przyjrzycie to nie tylko zmieszało adres z tej domeny, ale także inne strony o SEO, m.in. blog od +Eweliny. Zwracając uwagę na szczegóły, na stronie nie ma ani jednego linka. Wszystko to pourywane lub zmodyfikowane w czystej postaci tekstowej adresy URL. Wyciągając na szybko wnioski, Googlebot wziął te adresy za dobrą monetę, postanowił odwiedzić, a kiedy mu się to nie udało, zgłosił błąd 404 w Narzędziach dla Webmasterów. Po prostu pięknie! Pozostaje tylko liczyć, że Google nie traktuje tego błędu na niekorzyść domeny, która go zwraca.
John Mueller wspomniał o tej funkcji na początku września 2013, a cynk o tym pojawił się w wywiadzie z Łukaszem Żeleznym, który bacznie pilnuje wszystkich takich informacji, natomiast dzisiaj znalazł się dowód na działanie tego, jednak z miernym efektem dla Google i użytkowników.
Zapisz się na newsletter wypełniając pola poniżej. Będziesz na bieżąco ze wszystkimi wydarzeniami związanymi z Silesia SEM i informacjami o marketingu internetowym w sieci. Nie spamujemy.
Zostanie wysłany do Ciebie e-mail potwierdzający: przeczytaj zawarte w nim instrukcje, aby potwierdzić subskrypcję.
Artur Strzelecki
Ostatnie wpisy Artur Strzelecki (zobacz wszystkie)
- Festiwal SEO 2026 Katowice - 16 czerwca 2026
- Black Friday SEO 2025 - 28 listopada 2025
- Druga część webinaru z autorami książki „SEO w praktyce” - 25 listopada 2025


„John Mueller wspomniał o tej funkcji na początku września 2013”
Artur,
od dawna wiadomo przecież, że bot chodzi i indeksuje linki „nie urlowe” 🙂
Ale w czym szkodzą linki do 404? Albo mam za mało kawy we krwi, albo czegoś nie rozumiem?
Zauważyłem to 17 października, gdy Googlebot przeczytał mi plik txt i wyświetliły się „321 błędy” linków w GWT. Paranoja.
@Marek – bardzo dobre pytanie 🙂
Panda nie lubi linków 404 wychodzących.
Tylko jeśli prowadzimy stronę w której odwołujemy się do wielu źródeł zewnętrznych to z czasem tych błędów 404 może być sporo jeśli zostaną usunięte lub zmienione adresy.
Nie sądzę by takie linki pogarszały status naszej strony. Przecież gdyby tak było to można by wygenerować kilka tysięcy linków i komuś tak zaszkodzić. Jak bardzo kogoś boli taki link to może sobie dodać przekierowanie i po sprawie 😉